Apache Foundation, Twitter and (easy) distributed computing.
(объркващо заглавие на английски)
* всички правописни грешки са дело на автора
Кой?
Стан{,имир} Ангело{в,ff}
- Пише код.
- Обича бяло вино (без мярка).
- Не търпи глупави хора.
Hello!

The Apache Software Foundation
Community-led development since 1999.
![]()
Hadoop
Distributed computing
Hadoop: Ще е то?
Колекция от няколко проекта:
- Hadoop Distributed File System (HDFS)
- Resource Management (YARN)
- Hadoop MapReduce
Hadoop: Не само Java
Map/Reduce във всеки език, вкл. Bash, чрез Hadoop Streaming.
Hadoop Streaming пример
Map:
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s\t%s' % (word, 1)Hadoop Streaming пример
Reduce:
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
if current_word == word:
current_count += int(count)
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count) Hadoop: Топ 3 от добрите черти
- Сравнително лесен.
- Огромна база от потребители.
- Scaling horizontally.
Hadoop: Другите неща…
- Memory monster
- Много навързани системи
- Скрити изненади
![]()
Flume
Distributed service for collecting, aggregating, and moving logs
Flume: Що е то?
- distributed,
- reliable,
- based on streaming data flows,
- fault tolerant,
- tunable reliability mechanisms,
- failover and recovery mechanisms.
B.S.
Flume: Що е то?
- distributed,
- reliable,
- based on streaming data flows,
- fault tolerant,
- tunable reliability mechanisms,
- failover and recovery mechanisms.
B.S.
Flume: Що е то (v2)?
Бърз, лесен и надежден начин много редове текст да “прехвърчат” от много различни системи на едно централно място…
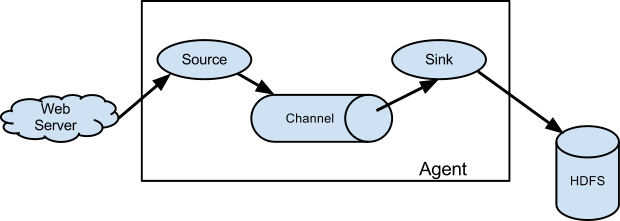
Flume: Защо и кога?
- Агрегация на данни от много източници
- Fan out, входна точна за данни, които трябва да достигнат до много системи
- Най-вече когато се работи с Hadoop/HDFS
Flume: Добрите черти
- Поддържа различни източници - syslog, HTTP/JSON, прост netcat сървър и т.н.
- Интегрира се с HDFS
Kafka
Distributed publish-subscribe messaging system
Kafka: Що е то?
Бързо queue/messaging с поддръжка за ТБ от данни.
Kafka: Кога?
- Най-вече при работа с Hadoop
- Като входна точка за друга система, която не може да приема голям обем от данни
- Pub-Sub
![]()
Sqoop
Big data <—> SQL
Sqoop: Що е то?
Копира/мести данни от HDFS в SQL и обратно.
Sqoop: Пример
Sqoop: Другите неща…
- Доста лимитиран откъм възможности и входен формат на данните
- Рано или късно ще ви се наложи да го компилирате с добавен feature - отнема часове!
Storm
Distributed real-time computation
Storm: Що е то?
Анализ на данни в real-time… с гаранция, че няма да се получават загуби.
Storm: Кога и защо?
- Generic и language-agnostic, покрива много use-cases
- Когато данните за дадено приложение трябва да са налични ASAP
Storm: Топ 3 от добрите черти
- Сравнително лесен, според авторите “Storm clusters just work”.
- Гарантира, че съобщенията са обработени на 100% без загуби
- Лесен за scale, повече машини > по-добра производителност
Storm: Другите неща…
- Не винаги “just works”
- Отново навързани системи
- Прекалено много термини специфични за проекта (топологии, streams, bolts, etc.)

ZooKeeper
Distributed coordination
ZooKeeper: Що е то?
Координация. That is all.
ZooKeeper: Пример
Как се генерира поредно ID в Hadoop MapReduce job в клъстър от 20 машини?
ZooKeeper: Добрите черти
- Изключително лесен за поддръжка, практически липсваща конфигурация.
- Йерархичен модел да данните
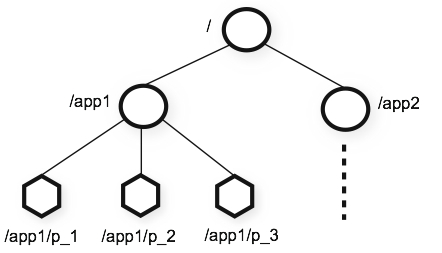
- Бърз, но при нужда scales easy - просто добавете още машини в ensemble-а.
Алтернативи
Ами сега?

Научете Java, ще ви трябва един ден.